【Python】ログインが必要なサイトをWebスクレイピングする方法

- はじめに
- Webスクレイピングする為のパッケージ&Chrome Driverをインストールする
- Google Chromeの検証機能(デベロッパーツール)を使ったHTML要素の調べ方
- Garmin Connectのログインページを表示するプログラムの実行
- Webスクレイピングのプログラムを進める為のポイント
動作環境
- Mac 10.11.6
- Python 3.7
-
取得したデータの保存先
XServer
MySQL 5.7
今回使用したパッケージ&ツール
- beautifulsoup4
- selenium
- Chrome Driver
- Google Chrome(事前にインストールしてください)
はじめに
日々のランニングではGarmin ForeAthlete230J を使って走行距離やラップタイムなどを計っています。練習後にはiPhoneとBluetooth接続してGarmin Connectに保存しています。
iPhoneのアプリからメモなども追記できるので、筋トレやその日の調子をメモしたり、シューズの管理などが簡単に出来るのですごく便利です。
このGarmin Connectの情報を自分の見やすい内容にした独自の練習日誌を作ってみます。最近、新しい言語なども勉強したいな~と思っていたので、よい教材となりそうです。
機械学習やAIなどで流行っている(もう古いかもしれませんが)らしいので、言語はPythonにします。Webスクレイピングなども簡単にでき向いている言語のようです。
簡単に処理の流れをまとめてみました。
Webスクレイピングする為のパッケージ&Chrome Driverをインストールする
今回、スクレイピングするGarmin ConnectのWebページはログイン認証や画面遷移などのブラウザの操作も自動で行います。そこでSelenium&ChromeDriverを使ってGoogle Chromeを操作していきます。
HomebrewからChrome Driverをインストール
以下のコマンドでHomebrewからChromeDriverをインストールします。
Google Chromeは別途インストールしてください。
Homebrewがインストールされていない場合は、こちらを参考にしてください。
$ brew install chromedriver
Seleniumをインストール
以下のコマンドを実行します。
仮想環境で実装する場合は、仮想環境をアクティブにしてください。
仮想環境をアクティブにする方法
$ pip3 install selenium
Google Chromeの検証機能(デベロッパーツール)を使ったHTML要素の調べ方
ブラウザの操作をする際には、対象ページのHTMLを調べる必要があります。
どうやったらそんなことできるの?という方も大丈夫です。
IEやChromeなどには開発用に検証機能が備わっています。
今回はGoogle Chromeでの検証機能の使い方を簡単に紹介します。
デベロッパーツールの起動方法
1.サンプルにAppleのホームページを開きます。
2.画面の任意の場所を右クリックします。
3.表示されたメニューの検証をクリックします。
4.画面にデベロッパーツールが開きます。
WebページのHTMLを調べる
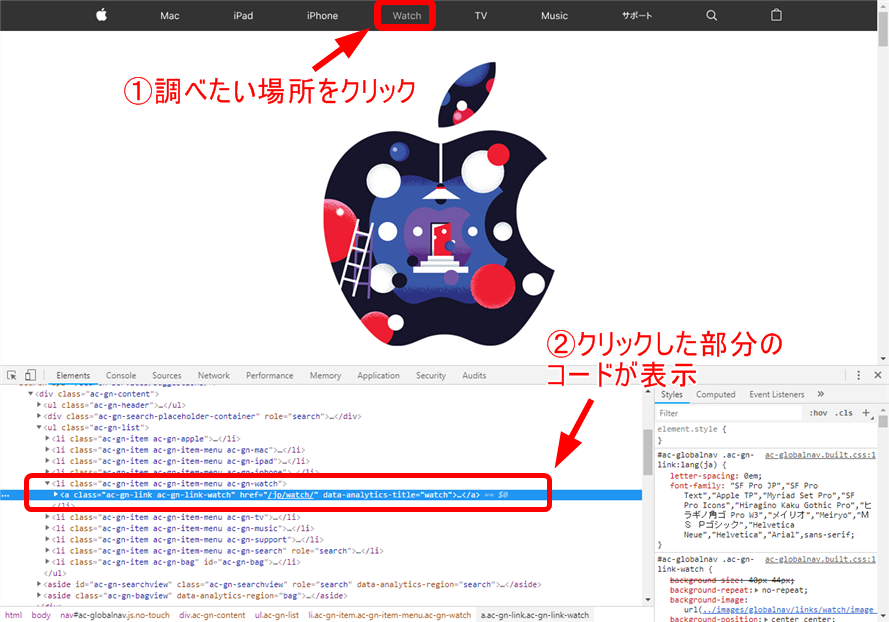
1.デベロッパーツールの左側にあるアイコンをクリック
2.調べたい場所をクリックします。するとデベロッパーツールにクリックした場所のコードが選択された状態で表示されます。
このようにして属性やCSSなどを調べていきます。
Garmin Connectのログインページを表示するプログラムの実行
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
try :
opt = Options()
# Headlessモードを有効にする
# 引数をTrueに設定するとブラウザを起動させず実行できます
opt.set_headless(False)
# Chromeを起動する
driver = webdriver.Chrome(chrome_options=opt)
# 指定した要素が見つかるまでの待ち時間を設定(20秒)
driver.implicitly_wait(20)
# Garmin Connectのページを表示
driver.get("https://connect.garmin.com/ja-JP/signin")
# iframe内のDOMを操作できるようにする
elm = driver.find_element_by_id("gauth-widget-frame-gauth-widget")
driver.switch_to_frame(elm)
# IDの入力要素を取得
elm = driver.find_element_by_id("username")
# IDを入力
elm.send_keys([IDを指定])
# パスワードの入力要素を取得
elm = driver.find_element_by_id("password")
# パスワードを入力
elm.send_keys([パスワードを指定])
# サインインボタンを取得
elm = driver.find_element_by_id("login-btn-signin")
# サインインボタンをクリック
elm.click()
# すぐ画面が消えてしまうので確認するために5秒スリープさせる
sleep(5)
except Exception as ex :
# 例外処理
print(ex)
finally:
# webdriverのインスタンスが生成されている場合、Chromeを終了
if "driver" in vars() and driver is not None :
driver.quit()
コードの解説
set_headless()でTrueを設定する事でブラウザを起動せず実行できます。
本番では設定するといいと思いますが、最初はFalseを設定して実行するといいと思います。
自分が書いたコードで実際にブラウザを操作する様子が見れて楽しいです。
opt.set_headless(False)
find_element_by_idなどで要素を検索してもページの読み込みが終わっていなくてエラーとなってしますことがあります。
sleepで待ち時間を設定しても良いですが、検索する都度実装しなくてはいけませんし、想定より早く読み込めた場合は無駄な時間を待つことになります。
implicity_waitは要素が読み込まれるまでの待ち時間を一律に設定することができます。また、要素を見つけたら処理は進むので多めの時間を設定しておくと良いです。
driver.implicitly_wait(20)
find_element_by_idは引数に取得したい要素のid属性を指定することで、最初に一致した要素を取得できます。
一致するid 属性の要素がない場合、 NoSuchElementExceptionが発生します。
elm = driver.find_element_by_id([要素のID])
「Garminアカウントにサインイン」内の項目はiframe内に配置されていて、何もしないとfind_element_by_idなどでIDやパスワードなどの要素が取得できません。
ここでかなりハマりました。
iframe要素を検索してswitch_to_frameを呼び出すことで、iframe内の要素を取得することが出来るようになります。
elm = driver.find_element_by_id("gauth-widget-frame-gauth-widget")
driver.switch_to_frame(elm)
任意の要素に対してsend_keysを呼び出すことで、テキストフィールドに指定した文字列を入力します。
elm.send_keys("PassWord")
任意のボタン要素に対してclickを呼び出すことで、ボタンをクリックします。
elm.click()
ブラウザのウィンドウを全て閉じます。
driver.close()は一つのウィンドウだけ閉じます。複数開いている場合はそれぞれ閉じる必要があります。理由がなければ、プロセスの解放漏れを防ぐ為にもquit()で一括に終了させましょう。
driver.quit()
Webスクレイピングのプログラムを進める為のポイント
1.Google Chromeなどの検証機能(デベロッパーツール)を使用して属性などを調べる
2.web driverを使用して表示したウェブページのソースをログなどに出力してHTMLを確認する
「web driverに表示されているのにfind_element_by_idなどを使って要素を取得するとエラーとなり見つからない」ということがよくあります。
見えている内容とプログラムで取得している内容が違う時、「なんで!!このページはスクレイピング出来ないの?」とハマってしまうことがよくありました。
今回のiframeの場合もそうです。他にもページを読み込んだ後にJavaScriptで加工するようなページやスクロールすると表示されるページなどでは、単純に[表示]->[要素の検索]では取得できません。
でも安心してください。Selenium+Chrome Driverのスクレイピングは、通常のブラウザ操作で行っている事はたいていの場合、自動化できます。
その切り分けとして、取得した内容をログなどに出力し、HTMLコードを確認してみてください。
思った要素が無い場合などは、switch_to_frameのようにひと手間加えることで解決するはずです。
# ログイン画面表示
driver.get("https://connect.garmin.com/ja-JP/signin")
# ページのHTMLコードを取得
html = driver.page_source
print(html)





![[解決済] Dell Precision T1700 の再インストール後にドライバーが入らない](https://chibashi.me/wp-content/uploads/2019/04/dell-precison-t1700-driver-1024x683.jpg)

Commentsこの記事のコメント
メールアドレスが公開されることはありません。お気軽にコメントどうぞ。